Metadata. You have probably heard the word mentioned often in the news recently. Consumer advocates are worried at the rate at which consumer’s metadata is being used by companies to track their browsing and purchase history for targeted advertising. Others are concerned about the potential for this information to also be tracked by the federal government.
That being said, what is metadata?
Scholars such as Anne J. Gilliland have described metadata as “data of data”–hence, the meta nature of it. She further breaks down metadata in her chapter for the book, Introduction to Metadata, as information related to the content, context, or structure of an object of inquiry.

Sounds a bit complicated, right? Basically, metadata consists of information related to a single item–a book, for instance–or a collection of them that helps to distinguish said objects from others, making them easier to find.
For libraries, archives, and other repositories of information, metadata is a crucial tool for organizing, indexing and making collections of texts, visuals, and other objects more accessible. Towards that goal, institutions utilize one data standard or another, each with their own rules concerning indexing, abstracts, and bibliographic records for their collections.
My classmate Bianca Barcenas mentioned in her blog this week (which I highly recommend reading to follow us along in our journey) how archives keep to a standard of metadata structure across the country. Indeed, the Society of American Archivists (SAA) recommends using MARC (“machine-readable”) cataloguing and Encoded Archival Description (EAD) for metadata concerning collections, as well as the Dublin Core for describing web resources.
Other students in the class have written about some of these standards. Zach Stella, in particular, wrote an interesting piece on the Dublin Core that goes a long way towards describing how it is designed to work for the vast amount of content on the web today.
One standard I wanted to further explore was EAD.
According to Gilliland, EAD was created in 1998 to accompany the MARC standard of describing bibliographic materials. The Society of American Archivists and the Library of Congress adopted EAD as a standard in 1999 and continue to issue instructions and updates on how to use the standard on a joint website.
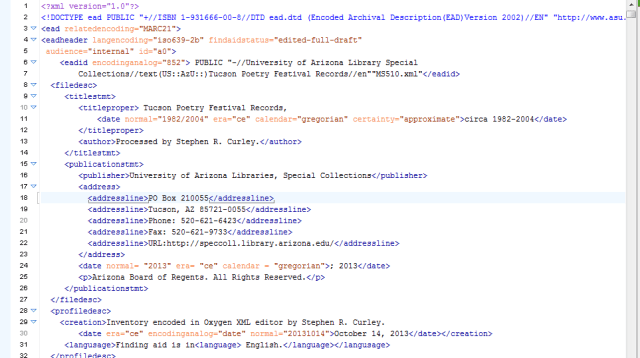
Upon first impression, the exact format of EAD can be difficult to navigate. As you can see in the example above, it contains information such as the collection one is searching within, the title of a work or collection of files, author, publisher, address of the location the object is being held, among others. It essentially follows a header and description format you would find common in coding.
The most recent version of EAD (named EAD3) released in 2010 attempted to simplify the language and categories for archivists to use (as the chart below provided by the Library of Congress attempts to demonstrate).
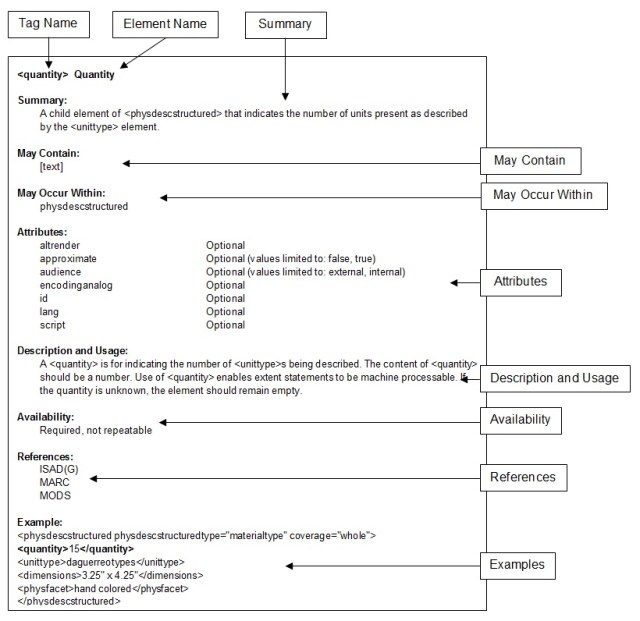
Evidently, both the Library of Congress and the SAA have taken steps to try to clarify the language and uses of EAD to make it more accessible to would-be archivists and researchers.
It is difficult to measure the success and longevity of EAD as a data structuring method. The XML format used by EAD to organize information can seem pretty straightforward for people with a background in coding, but prove very hard for researchers without that experience (myself included) to navigate and integrate.
Ultimately, organizations may well choose one standard over another not because of objective differences in quality, but based on the extent of their technological exposure and agendas. Some may prefer Dublin Core for the ease of writing metadata along a list of “Core Elements” (Creator, Description, Type, Rights, etc.). Other institutions, including Loyola’s own Cudahy library, may continue to use older, digit-based systems such as MARC because it is familiar to them.
In the end, EAD is just another tool available at the hands of digital historians and archivists to sift through, to catalogue, and to find information of interest. Mastering one or another method of creating and browsing metadata, while a bit of a hurdle for some, may prove to be necessary for museums, libraries, and archives to further their information of storing, understanding, and making information attainable to the public.

Thanks for the shout out! I have to say, I find it ironic that many of the people behind these metadata initiatives have a mission to make information around objects more available, but through pushing these overly complex and technical information structures, have seemed to actually distance a lot of people from engaging with that information on a deeper level…
LikeLike